Bisheng Yang, Zhen Dong, Yuan Liu, Fuxun Liang, Yongjun Wang
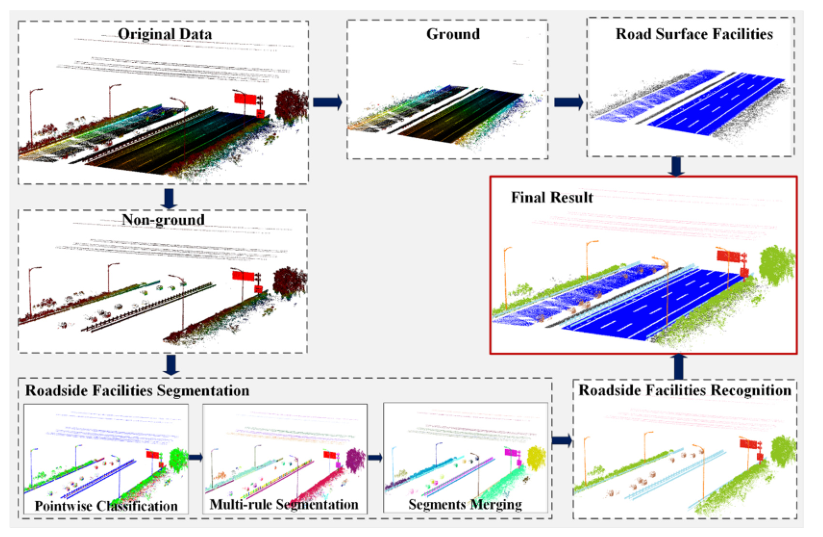
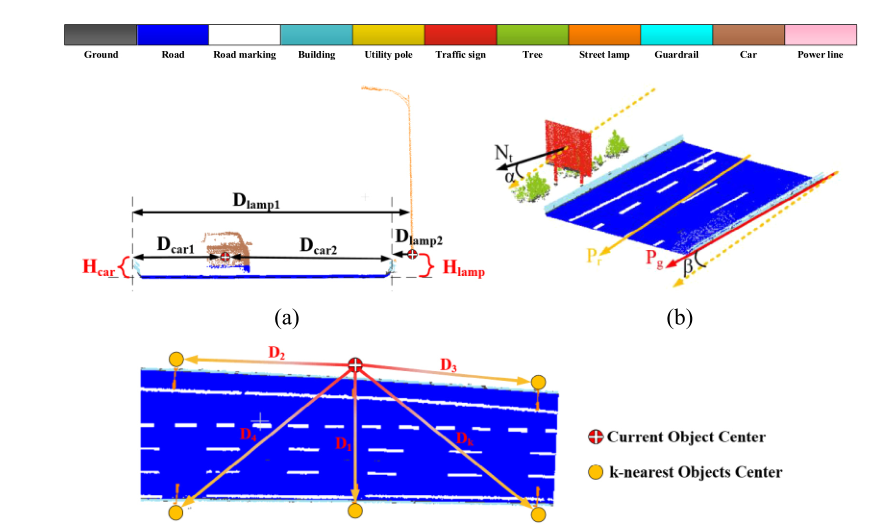
Abstract:In recent years, updating the inventory of road infrastructures based on field work is labor intensive, time consuming, and costly. Fortunately, vehicle-based mobile laser scanning (MLS) systems provide an efficient solution to rapidly capture three-dimensional (3D) point clouds of road environments with high flexibility and precision. However, robust recognition of road facilities from huge volumes of 3D point clouds is still a challenging issue because of complicated and incomplete structures, occlusions and varied point densities. Most existing methods utilize point or object based features to recognize object candidates, and can only extract limited types of objects with a relatively low recognition rate, especially for incomplete and small objects. To overcome these drawbacks, this paper proposes a semantic labeling framework by combing multiple aggregation levels (point-segment-object) of features and contextual features to recognize road facilities, such as road surfaces, road boundaries, buildings, guardrails, street lamps, traffic signs, roadside-trees, power lines, and cars, for highway infrastructure inventory. The proposed method first identifies ground and non-ground points, and extracts road surfaces facilities from ground points. Non-ground points are segmented into individual candidate objects based on the proposed multi-rule region growing method. Then, the multiple aggregation levels of features and the contextual features (relative positions, relative directions, and spatial patterns) associated with each candidate object are calculated and fed into a SVM classifier to label the corresponding candidate object.The recognition performance of combining multiple aggregation levels and contextual features was compared with single level (point, segment, or object) based features using large-scale highway scene point clouds. Comparative studies demonstrated that the proposed semantic labeling framework significantly improves road facilities recognition precision (90.6%) and recall (91.2%), particularly for incomplete and small objects.
Keywords:Point clouds processing,Object recognition,Contextual features,Multiple aggregation levels features,Semantic labeling

Download