标题:道路点云场景双层卷积语义分割
Bilevel Convolutional Neural Networks for 3D Semantic Segmentation Using Large⁃scale LiDAR Point Clouds in Complex Environments
作者:蒋腾平,杨必胜,周雨舟,朱润松,胡宗田,董震
来源:武汉大学学报·信息科学版 (Geomatics and Information Science of Wuhan University)
摘要:在大规模道路环境中,基于点的语义分割方法需要动态计算,而基于体素的方法权衡分辨率和性能导致损失大量信息。为了克服上述两类方法的缺陷,提出了一种通用的结合双层卷积和动态边缘卷积优化的网络架构来进行大型道路场景语义分割。该框架结合点与超体素两种不同域的卷积运算来避免冗余的计算和存储网络中的空间信息,并结合动态边缘卷积优化,使其端到端地一次性处理大规模点云。在不同场景的数据集上对该方法进行了测试与评估,结果表明,该方法能适应不同场景数据集并取得较高精度,优于现有方法。
研究意义
随着激光雷达技术的快速发展,点云的获取越来越便利,数据的规模也愈加庞大。如何从海量点云数据中获取有用的信息,更好地实现场景理解,是目前点云智能化研究的重要内容,而三维点云语义分割则是该领域的基础。为了能够准确描述空间中物体的类型,需要对每个道路目标进行分割,赋予每个道路目标特定的含义。这项工作就是点云语义分割,也就是给点云中的每个点赋予特定的语义标签。所赋予的语义标签在真实世界中是有意义的,这使我们能对道路场景进行更加细致的了解,如下图的交通杆状设施被赋予为标签3,同时使用红色标记并可视化,这有助于实现场景理解。

图1. 语义分割后的道路点云场景可视化
研究现状
基于传统机器学习模型(如图2所示)进行点云语义分割,通常从设计手工特征开始,如几何特征、辐射特征、拓扑特征和回波特征等,然后通过使用基于机器学习的分类器(包括支持向量机、随机森林、马尔可夫随机场和条件随机场等)进行点云分类。但是,这些手工特征的计算需要特定的先验知识,并且从原始点云提取有效特征的能力有限。总体来说,传统机器学习方法在复杂场景下效率低且精度有限。
图2. 基于传统机器学习模型的点云分类代表性架构
不同于传统的机器学习机制,深度学习方法对点云特征和分类器共同学习。但是,由于非结构化点云与常规图像不同,很难直接应用卷积神经网络(convolutional neural network,CNN)来分析点云数据。因此,基于深度学习的方法主要在于数据的表达。基于多视图可以直接利用基于图像的 CNN进行处理。但是,尚不清楚如何确定视图数量以及如何分布这些视图,使得覆盖 3D 形状的同时避免自遮挡。基于体素的方法是将非结构化点云转换为可应用常规卷积网络的体素结构。如果分辨率较低,会丢失信息,因此需要高分辨率以保留数据的细节信息,但随着体素分辨率的提高,存储和计算成本也随之提高。基于点的方法往往都通过聚合每个点的邻近特征来提取逐点特征,通过最近邻域搜索建立索引解决相邻点不会连续存储的问题。这种时间换空间的方式增加了内存成本,邻域随机的相对位置也会增加动态内核计算。
受到point-voxel CNN模型(如图3所示)的启发,本文结合基于体素和点两个方法的优势,先将点云表达为超体素来降低稀疏性,以减少内存占用;然后采用一种新颖卷积模型进行端到端学习。

图3. point-voxel CNN模型示意图
研究方法
本文方法主要包含3个模块:能量驱动的超体素生成与表示、基于点-超体素双层卷积网络的特征提取及融合、动态边缘特征提取优化。
能量驱动的超体素生成与表示
传统体素化严重依赖点之间的固有相邻关系,超体素提供紧凑且在感知上有意义的表示形式,这对后续的点云目标识别大有裨益。超体素不仅分布均匀,而且最近邻域基本覆盖城市场景中足够大的区域,提取有意义的局部上下文信息进行语义分割。
为了改善分布不均并有效降低计算复杂度,本文采用能量驱动方式将具有相似特征的相邻点合并成近似相等分辨率的齐次超体素,更好地保留对象边界。图3显示了超体素生成结果示例。超体素将作为体素分支处理单元,每个超体素内的点都被认为具有相同语义标签。基于超体素的场景重组改善了原始输入端,但仍然难以清晰地描述每个超体素属性。为了解决该问题,本文采用直接面向超体素的稀疏自动编码,以数据驱动方式压缩和编码每个超体素的嵌入表示。具体地,基于相对熵有效压缩超体素的重要特征,通过最大池化合成全局特征并嵌入超体素的空间位置以增强空间关系表达。

|

|
(a) 原始数据 |
(b) 超体素点云 |
图3. 超体素的生成
基于双层卷积的目标识别
本文网络由两部分组成(图4),一部分对低分辨率超体素进行卷积处理,提取粗粒度邻域信息;另一部分补充了基于点的细粒度特征提取,由于不汇总邻域信息,因此可以提供较高分辨率。

图4. 本文网络架构示意图
本文网络关键部分是聚集邻近信息以提取局部特征,在超体素域中执行特征聚合,从而以较高效率实现,大致网络架构见图5。

图5. 基于超体素与注意力机制相结合的图卷积网络示意图
这里采用一种结合注意力机制的图卷积网络,它是一个即插即用模块,可以轻松移植到其他网络模型。首先构造一个邻接图G ={V,E}来建模超体素之间的相邻关系,以促进相关区域的形成,超体素中心被视为顶点V ={ },并在每对相邻超体素之间建立边缘E ={
},并在每对相邻超体素之间建立边缘E ={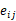 }。输入特征向量被定义为节点的初始化状态,并表示为f = {
}。输入特征向量被定义为节点的初始化状态,并表示为f = {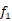 ,
, 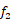 , …,
, …,  }。通过在每个点周围建立一个简单的局部连接关系,以确定特征转移方向,而不包含其他信息。图注意力机制模块通过计算节点之间特征空间中的关联度为不同节点指定不同权重。在后续过程中,需要将信息与基于点的特征融合,因此将基于超体素的特征转换回点云域。本文的超体素生成和去体素化是层次化步骤,互不影响,可以端到端地优化整个基于超体素的特征聚合。
}。通过在每个点周围建立一个简单的局部连接关系,以确定特征转移方向,而不包含其他信息。图注意力机制模块通过计算节点之间特征空间中的关联度为不同节点指定不同权重。在后续过程中,需要将信息与基于点的特征融合,因此将基于超体素的特征转换回点云域。本文的超体素生成和去体素化是层次化步骤,互不影响,可以端到端地优化整个基于超体素的特征聚合。
基于点特征和汇总的局部信息,两个针对点云不同表达方式的网络可以有效融合。特征融合主要分为两个组件,首先由输入特征提取模块生成的逐点特征与超体素空间获取的局部特征融合,弥补最大池操作造成的损失;然后由卷积层对n×1024的局部特征进行卷积,并与n×64的逐点特征融合,然后馈送到卷积层进一步提取特征信息,并应用归一化函数以生成权重图。将第一次融合结果与逐点特征融合,产生细粒度语义特征以改进分类的准确性;逐点特征同步由卷积层更新,与权重图相乘后添加到乘法结果产生新特征。与直接串联方式相比,本文方法将一些成熟的基于点网络直接嵌入,无需修改现有的配置,进一步提高了网络的灵活性。
动态图边缘卷积优化
尽管嵌入基于点和超体素双层融合框架可以获取多层次点云特征,但其并未考虑点与其邻域范围之间的边缘特征。基于K最近邻的自适应图卷积神经网络可以进一步提取点邻域内高层次局部边缘特征。本文采用一种动态图边缘卷积描述符捕获局部几何边缘结构。首先利用一种U形采样层次架构在全局和局部范围内获取高层次特征,将点云采样为各种分辨率,将特征从采样点云传播到相对密集的点云;然后构造一个局部邻域图,在连接的边上进行基于点特征的卷积计算。
通过将动态图边缘卷积添加到本文模型中,不仅考虑了几何信息,而且还考虑了某个点与其相邻点之间的边缘信息特征,以捕获局部区域中的更多描述性特征。
实验结果
本文在城市环境和京承高速公路两个大规模室外点云场景上进行测试。为了验证本文模型的鲁棒性,还在室外激光点云Semantic3D和室内RGBD点云S3DIS两个基准数据集进行测试。对于自身采集的两个数据集,本文利用精确度和召回率对语义分割结果进行质量评价,对另外两个基准数据集根据自身评估矩阵IoU(intersection over union,衡量预测值和真实值之间的重叠度),多次实验对本文模型的性能进行了评估。
图6、图7和图8分别显示了本文方法在城市环境、高速公路、室外Semantic3D 点云数据集和室内 S3DIS 点云数据集的实验结果。
图6. 城市环境语义分割结果
图7. 高速公路环境语义分割结果
图8. semantic3D和S3SID基准数据集语义分割结果
表1、表2和表3分别显示了本文方法在上述数据集的结果,同时还列出了与一些有代表性方法的比较结果。
表1 城市/高速场景数据精度对比/%
方法 |
城市场景 |
高速场景 |
精确 |
召回 |
精确 |
召回 |
Ours |
94.9 |
93.8 |
91.1 |
91.5 |
[34] |
/ |
/ |
90.6 |
91.2 |
表2 Semantic3D 数据精度比较/%
方法 |
mIoU |
草坪 |
地面 |
树木 |
灌木 |
建筑 |
花坛 |
设施 |
车 |
[37] |
67.5 |
86.8 |
80.9 |
88.1 |
50.6 |
93.4 |
32.8 |
41.3 |
69.5 |
[38] |
61.3 |
83.9 |
66.0 |
86.0 |
40.5 |
91.1 |
30.9 |
27.5 |
64.3 |
[39] |
70.8 |
86.4 |
77.7 |
88.5 |
60.6 |
94.2 |
37.3 |
43.5 |
77.8 |
Ours |
73.2 |
97.4 |
92.6 |
87.9 |
44.0 |
93.2 |
34.7 |
63.5 |
79.7 |
表3 S3DIS 数据精度比较/%
方法 |
miou |
屋顶 |
地板 |
墙面 |
梁 |
柱 |
窗户 |
门 |
椅子 |
桌子 |
书柜 |
沙发 |
面板 |
其它 |
[37] |
49.7 |
90.3 |
92.1 |
67.9 |
44.7 |
24.2 |
52.3 |
51.2 |
47.4 |
58.1 |
39.0 |
6.9 |
30.0 |
41.9 |
[38] |
52.5 |
90.6 |
90.1 |
74.2 |
31.3 |
29.0 |
46.6 |
61.9 |
54.9 |
56.6 |
45.4 |
16.6 |
34.9 |
46.8 |
[40] |
56.5 |
92.5 |
92.8 |
78.6 |
32.8 |
34.4 |
51.6 |
68.1 |
59.7 |
60.1 |
50.2 |
16.4 |
44.9 |
52.0 |
Ours |
60.2 |
92.2 |
96.9 |
82.6 |
46.5 |
34.6 |
51.7 |
40.1 |
85.3 |
78.9 |
69.5 |
54.2 |
60.2 |
54.5 |
针对现有方法在大规模点云场景语义分割的计算复杂性高和鲁棒性不足等问题,本文首先生成超体素及基于SAE嵌入表示,然后协同基于点和超体素进行卷积处理,最后通过动态边缘图卷积学习点与相邻点之间的边缘特征。本文模型能兼顾点和超体素两种点云表达形式的性能和效率。通过相关指标比较表明,在4个不同场景(两个真实室外场景,两个基准数据集)中,本文框架的语义分割精度优于现有前沿方法(基于手工特征的机器学习算法和4种具有代表性的深度学习方法)。
Abstract:
In large scale road environment, point-based methods require dynamic calculations, and voxel-based methods often lose a lot of information when balancing resolution and performance. To overcome the drawbacks of the above two classical methods, this paper proposes a general network architecture that combines bi-level convolution and dynamic graph edge convolution optimization for multi-object recognition of large scale road scenes. The framework integrates the convolution operations of two different domains of points and supervoxels to avoid redundant calculations and storage of spatial information in the network. Coupled with the dynamic graph edge convolution optimization, our model enables it to process large scale point clouds end-to-end at once. Our method was tested and evaluated on different datasets. The experimental results show that our method can achieve higher accuracy in complex road scenes, which is superior to the existing advanced methods.
点击获取原文